At the MilCIS 2024 session “The Art of Troubleshooting – Practical Advice for a Repeatable, Disciplined Approach to Proactive and Pre-emptive IT Troubleshooting,” I shared my insights on improving IT service quality and reducing the time required to resolve issues. The session offered actionable strategies for IT professionals striving to streamline troubleshooting processes in increasingly complex environments.
Troubleshooting: art, science or both?
Troubleshooting IT issues is often seen as an art due to the creativity required to navigate unfamiliar challenges. However, it’s equally a science. By balancing art and science, organizations can significantly improve their approach to IT troubleshooting.
The art of troubleshooting involves intuition, creativity, and experience. IT professionals rely on these qualities to adapt to unforeseen problems and explore innovative solutions. On the other hand, the science of troubleshooting demands a disciplined, repeatable process. Preconfigured tools, dashboards, and workflows ensure consistency and efficiency.
Why troubleshooting takes so long
Two key factors often delay IT troubleshooting:
- Complexity: Modern IT ecosystems involve diverse users, locations, platforms, and protocols, such as Zero Trust architectures. These elements add layers of intricacy, create gaps in visibility, and complicate root cause analysis.
- Lack of preparation: Organizations frequently lack updated documentation, sufficient telemetry, or preplanned workflows. New applications may be deployed without comprehensive visibility or performance management strategies.
A structured approach to troubleshooting
To address these challenges, I recommend adopting a scientific, repeatable process built on four key pillars:
- Preparation and onboarding:
- Monitor assets and onboard applications to ensure visibility from deployment.
- Maintain updated architectural documentation for quick reference during incidents.
- Instrumentation and telemetry:
- Define key performance indicators (KPIs) and collect granular telemetry data.
- Use custom dashboards and daily performance reports to establish baselines for normal operations.
- Workflow and process:
- Map out troubleshooting workflows for each application or service, identifying where to look and what data to analyze.
- Integrate change management protocols, defining rollback criteria and measuring performance impacts.
- Continuous improvement:
- Review every incident to refine processes and address visibility gaps.
- Foster collaboration among teams, such as security, cloud, and virtualization, to ensure alignment and shared understanding.
Getting on the same page: a performance troubleshooting taxonomy
For maximum effectiveness, organizations must adopt a structured framework to standardize the process of 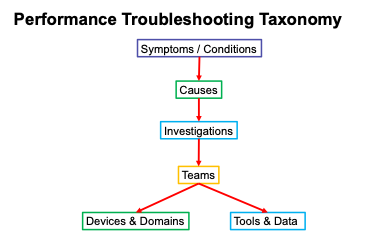 diagnosing and resolving issues. This framework aligns teams, simplifies workflows, and sets the stage for automation. Key considerations include:
diagnosing and resolving issues. This framework aligns teams, simplifies workflows, and sets the stage for automation. Key considerations include:
- Symptoms and conditions: What are you observing?
- Possible causes: What might be contributing to the issue?
- Investigations: What steps will you take to identify the root cause?
- Devices and domains: Where might you need to look?
- Tools and data: What tools and data will you use?
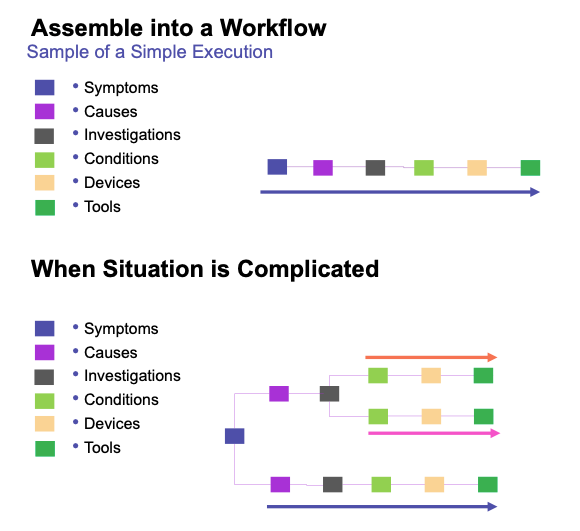
In simple cases, this approach can lead to a single streamlined workflow. In more complex scenarios, however, multiple issues, potential root causes, and investigations may require collaboration across teams from different domains, resulting in more intricate workflows.
Real-world example: resolving a network performance issue
A real-world case study illustrates the value of a structured troubleshooting approach. A global organization was experiencing poor file transfer performance, causing weeks of frustration, missed deadlines, and decreased productivity. The root cause was initially unclear, and the investigation involved several pivots. Here’s how the issue was resolved:
- Initial investigation: Symptoms included slow file transfers impacting productivity. The team started with user feedback and monitoring tool data.
- Data analysis: Telemetry revealed no retransmissions at one site but inconsistent traffic visibility at another, suggesting a network configuration issue.
- Root cause: The investigation uncovered misconfigured SD-WAN tunnels caused by a simple typo, leading to routing asymmetry and degraded performance.
- Outcome: Correcting the misconfiguration resolved the issue, restoring performance and enabling effective use of available bandwidth.
During the investigation, these Riverbed solutions played a crucial role:
- NetProfiler: Enterprise-wide flow collection, analytics, and reporting.
- AppResponse 11: Real-time packet-based performance monitoring, analytics, and packet capture.
- Packet Analyzer Plus: Fast, focused performance analysis of large capture files.
- Transaction Analyzer: Detailed decodes, advanced performance analytics, and transaction simulations.
This case underscores the importance of visibility, collaboration, and disciplined processes in troubleshooting complex issues.
Recommendations for IT teams
To enhance troubleshooting efficiency and minimize downtime, I recommend the following steps:
- Invest in visibility tools: Ensure comprehensive observability across the IT stack.
- Adopt proactive practices: Preconfigure dashboards, alerts, and workflows before problems arise.
- Foster collaboration: Align cross-functional teams with shared processes and communication strategies.
- Document and iterate: Maintain living logs of investigations and continuously refine processes based on lessons learned.
Troubleshooting is both an art and a science, requiring creativity and discipline to solve problems effectively. By adopting a structured, repeatable approach, IT teams can improve service quality, reduce resolution times, and better support mission success. As I summarized during the session, reducing time to troubleshoot starts with preparation, collaboration, and a commitment to continuous improvement.
For further information, contact your Riverbed account manager or check out the Riverbed Performance Foundations Course.